本文将介绍seq2seq模型以及机器翻译的内容,需要明白RNN模型
RNN介绍的文章看这里:https://blog.csdn.net/zhaojc1995/article/details/80572098
为什么需要RNN?
- 时序数据:语音、天气、股票、文本
- R’n’n
seq2seq
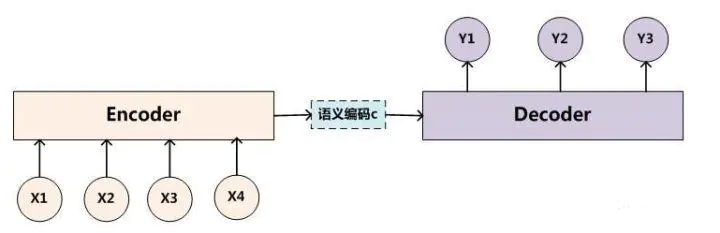
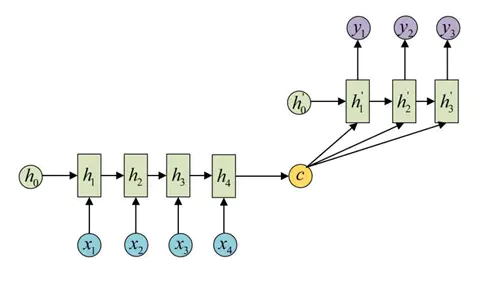
seq2seq(sequence to sequence)故名思意就是一种能够根据给定的序列,通过特定的方法生成另一个序列的方法,属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
seq2seq应用在机器翻译、对话机器人等领域,后续会补充一些项目实战,下面先介绍一下基础思路
seq2seq训练
训练数据为<中文,英文>,然后我们将每个minibatch中语句的长度补成相同(与最大长度相同),不同的minibatch不要求相同长度,这样方便进行向量化矩阵化(matrix)操作,
infereence/Decoding
如果我们已经训练好了模型参数,怎么生成语句序列呢呢?
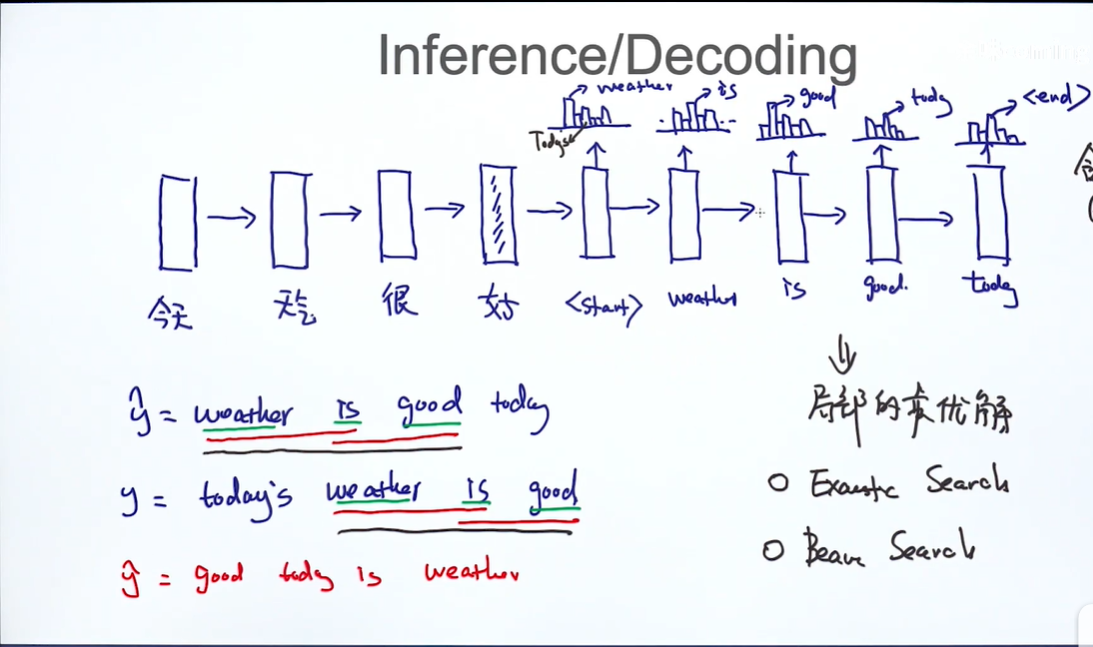
通过模型softmax,我们可以得到每个单词的概率分布,然后每次选取概率最大的作为生成词(greedy),但如果我们只考虑每个单词(unigram),即使生成的语句单词相同,但是如果顺序不同就会不通顺,即没有好的语法结构,所以可以用bgram。
如何改进只能考虑局部最优解的局限性呢?下面有两个改进想法,exhaustic search,beam search
exhaustic search
就是每次都考虑所有单词的情况,而不是只选择概率最高的单词,这样肯定可以找到全局最优解,但是这样就会复杂度很高,为
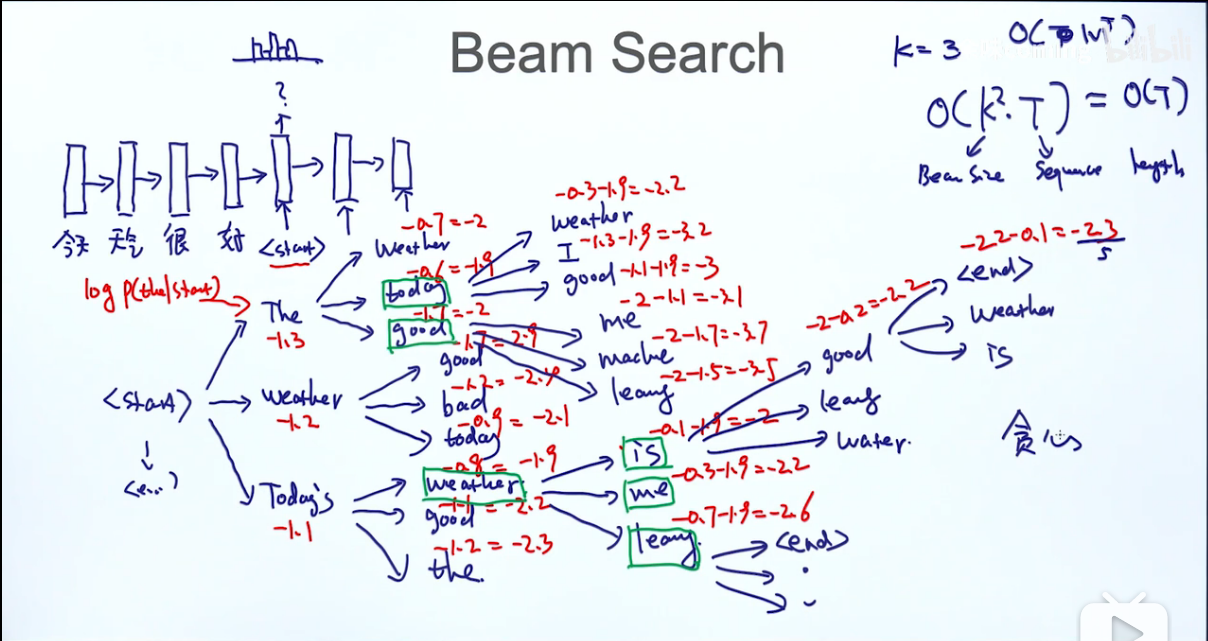
beam search
exhaustic search复杂度太高,我们考虑使用beam search,这种方法是既考虑了贪心算法的改进也对复杂度降低,如果我们设三种方法的最优解是,,,那么
beam search的想法是每次只考虑最好的k个单词,接下来是对第一次最好的k个单词继续考虑第二个生成单词也是取概率最高的前k个,但如果这样继续下去又是指数级增长了,所以是取对目前的序列(目前也就是长度为2)的概率和(其实是概率的乘积,但因为取了log)最高的k个序列,最后直到序列预测到end时停止,这样考虑也是有局限的,因为可能有的序列到很短就停止了,这样他的值就很大,最优解会优先选他,所以这块我们对每个序列除以长度。
每一步最多考虑个可能性,这个算法的复杂度为
代码实现
这里附上pytorch官方的实现:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
transformer
我们知道同一个单词可能在不同的语境中可能有不同的意思也就是需要不同的向量表达,这个表达依赖于上下文的意思,其他单词也影响着这个单词的意思,
为什么需要self-attention?
lstm的不足:
- long-term dependency
- 只能串行
transformer:
两两个都能考虑到

