本文我们将讲解注意力机制在视觉和自然语言以及图挖掘领域的使用。
PyTorch:https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
mutimodal learning
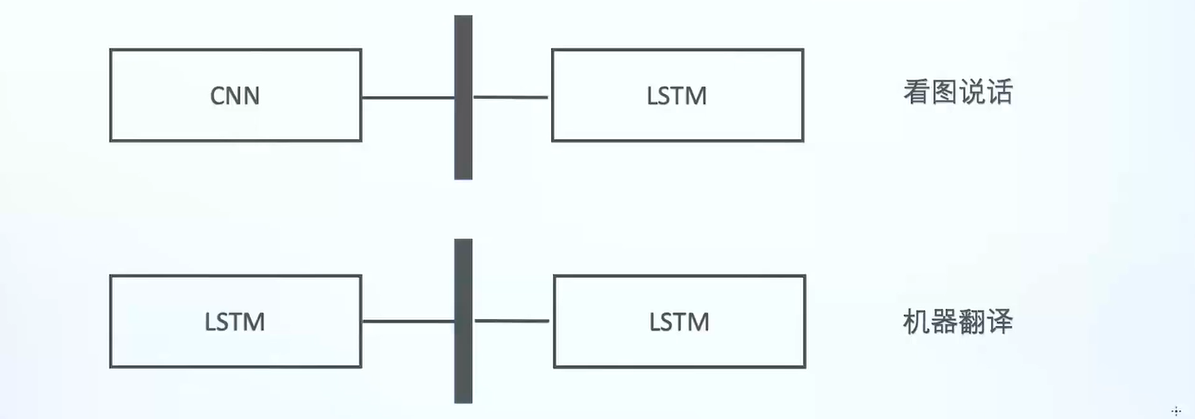
即将多个模型连接起来,每个模型完成相应的任务,一起完成比如看图说话、提取摘要等任务。
attention(注意力机制)
将注意力放到重要的地方,比较符合人类的思考,可以应用在文本、图像、自注意力(self-attention)
看图说话
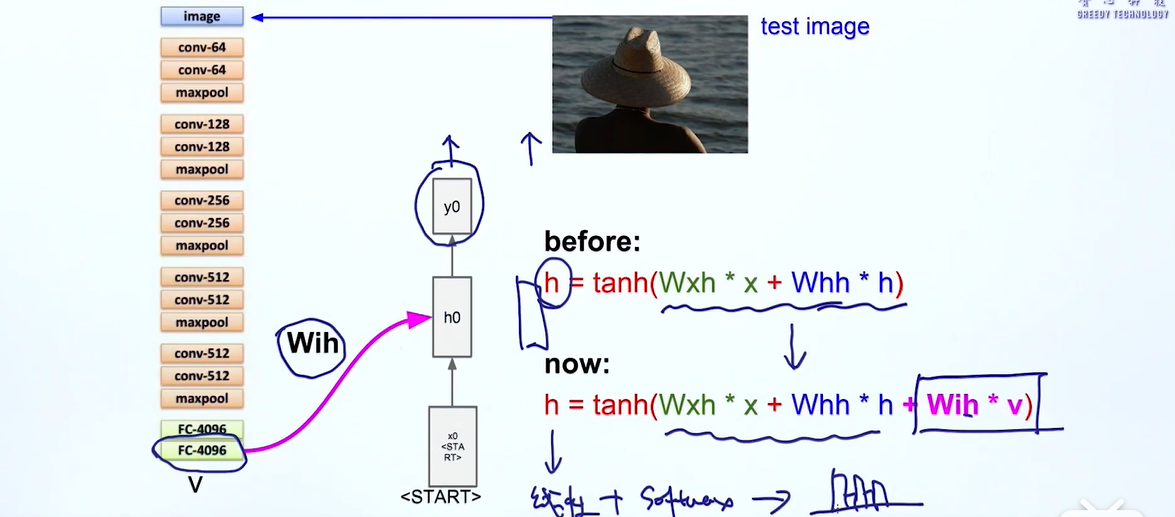
先把图片提取出一个向量作为桥梁,我们取模型中倒数第二个向量v,wih是一个转移矩阵,输入到RNN中来生成语句序列
但这模型有些问题,
- 识别不出来某些物体
- 我们把图片等价于一个向量,通过这个向量来生成,其实有时候我们只需要关注图片中的一直猫,不需要理解整张图片
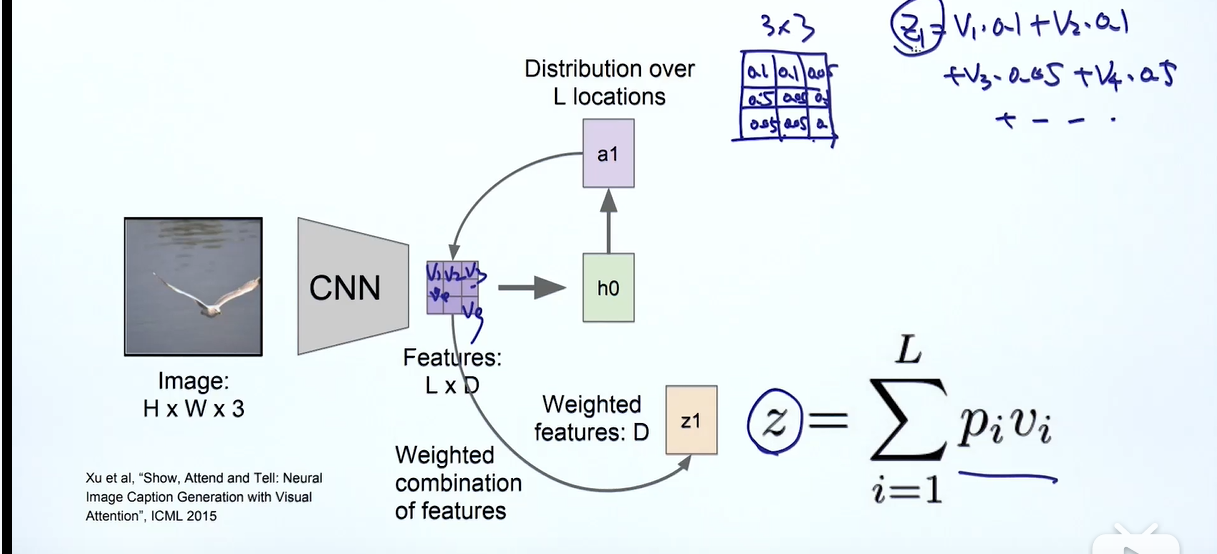
图像识别的注意力机制
这里feature矩阵每个格子都是一个d维的向量,a1也是一个3×3的矩阵,每个格代表这个区域的权重,当我们生成第一个单词我们要将注意力放在概率最高的区域,然后将这个两个矩阵的信息进行汇集到向量,较于之前的seq2seq模型,我们这里就多了一个
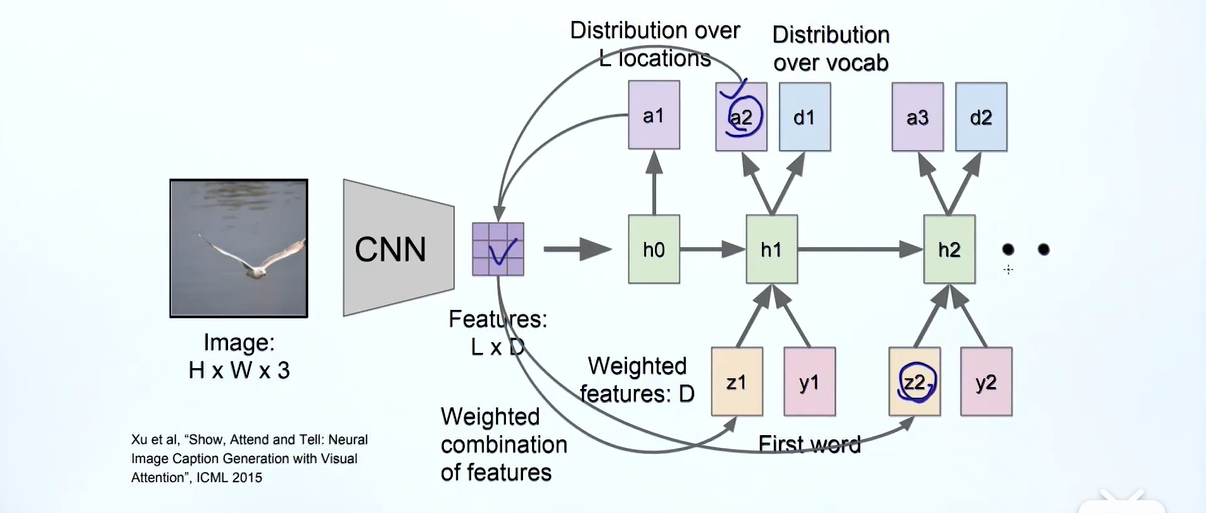
我们将输入到rnn模型,这里的first word就是start ,通过h1输出第一个单词和第二个单词的注意力,然后再生成,这里的就是的
https://blog.csdn.net/shenxiaolu1984/article/details/51493673#fn:1
attention in seq2seq
seq2seq的不足:
- 梯度问题
首先我们的语义编码c,我们的目的是希望这个向量能包括所有输入的单词信息,但是因为LSTM梯度消失的问题,c可能只能捕获离他较近的几个单词的信息,前面的单词可能就考虑不到了(怎么改进?给前面的单词分配一个权重——–attention) - 应用角度
现在的模型,我们生成下一个单词是依赖于上一个单词(pre)以及语义编码c,即,然而往往我们在翻译的时候只会关注句子的一部分,并且这种模式太过于依赖语义编码c,如果c的效果不理想,那么最后的decoder也会不理想,这也是bottleneck problem。还有一个原因,c向量的维度已经固定,对不同长度的输入句子,都用一个固定维度的向量表达难免不足
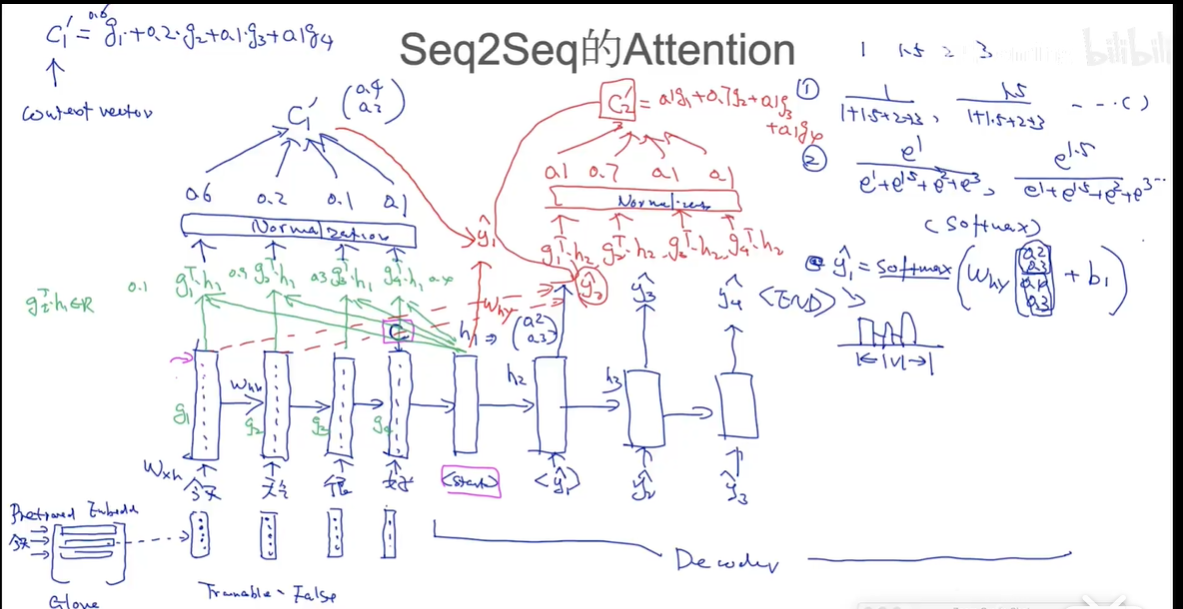
seq2seq的attention
下面这幅图讲解了大致流程,首先看encoder部分这里的隐含向量g是什么,举个例子,按照图的描述,就是transformation,f是激活函数,。
我们要使用注意力,就要给每个词一个attention score,最简单的就是和的内积,当然也可以设置别的函数,比如,这里的M就是要学习的一个参数矩阵。
我们以内积的方法为例,通过计算每个我们得到了每个单词的一个权重,然后通过归一化(可以是简单的通分,也可以是softmax)。
现在我们如何生成单词呢?首先先通过attention scroe,来生成新的context vector ,用来生成翻译单词(之前我们用的是),按图中的例子就是,然后我们将和拼接起来,来得到输出的单词,(就是v维度的,选取概率最大的单词作为预测词),之后类似,作为第二个预测单词的输入
attention的优点:
- 解决了梯度问题
- 可解释性(深度学习缺乏理论支持,大多参数的选择都是随机调,所以可解释学习也是当前的一个方向).
没有attention,我们无法可视化,无法看到模型的不足点去修改,有了attention我们可以针对性的解决,比如拿一句话今天天气很好,我们的模型把今天翻译成了yesterday,那么我们可以看一下今天的attention score,如果很高说明方向是对的,可能是样本数据的问题,如果权重小也就是其他词的权重大了,那么这个模型就是有问题了
attention的不足:
attention in seq2seq的不足:
我们这种思路是给每个单词一个权重,我们更希望每个单词是独立的,然而RNN的特性,当前单词又会汇集之前的单词信息,这也是一个矛盾点,
- 想法一:g2-g1?来去除冗余信息?当然这是不对的,因为向量的表达相当于是空间中的一个位置,向量的差值没有什么含义,有方向的,方向是不能减的。

