seq2seq主要有下面两个不足:
- long—term dependency 会出现梯度消失或者爆炸
- 只能串行 时序的模型,后面的运算必须依赖于前面的运算
我们知道同一个单词可能在不同的语境中可能有不同的意思也就是需要不同的向量表达,这个表达依赖于上下文的意思,其他单词也影响着这个单词的意思,
transformer就改进了这块的不足。
transformer的优点
RNN会将它已经处理过的前面的所有单词/向量的表示与它正在处理的当前单词/向量结合起来。而自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。
Encoder

encoder 主要有两部分部分,一个self-attention另一个就是全连接网络,self-attention进行不同单词之间信息的交互,具体下面来讲,而全连接网络就是对每个单词进行的转换,也就是乘上一个矩阵再加上偏置,然后再加上激活函数。
所以encoder主要再self-attention
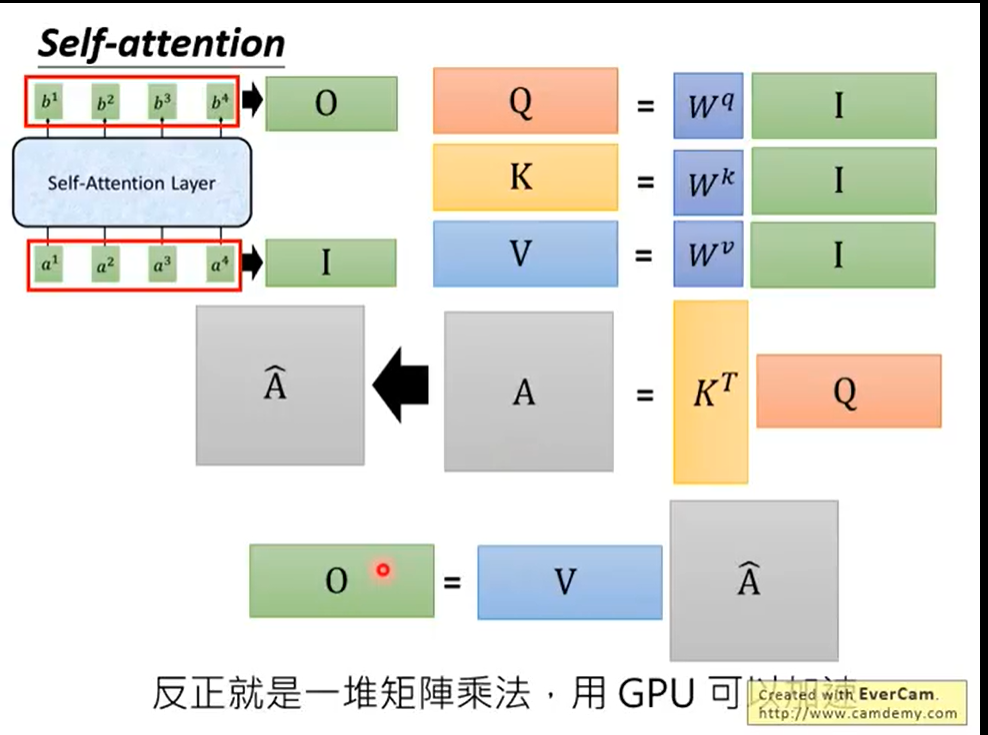
首先输入就是每个单词的embedding,比如可以是glove训练出来的,然后有三个参数矩阵,,这是共享的参数矩阵,然后输入向量分别与三个矩阵相乘,得到三个向量,,这里的向量是一个比原始embedding向量更加低维的表达,这就是两个单词的attention,比如其中两个值是112、96,如果我们直接用和的归一化,则这两个值会比较接近,梯度更稳定,如果直接送到softmax,,,这两个值就会分别接近0和1了,没有区分度,所以这里我们对他除以一个,就是的维度(论文里是8,也就是64维度的求根值)再进行softmax,然后对每个atteention值(这些值也可以当作是一个score向量)分别与对应的相乘得到,,具体可见下图,
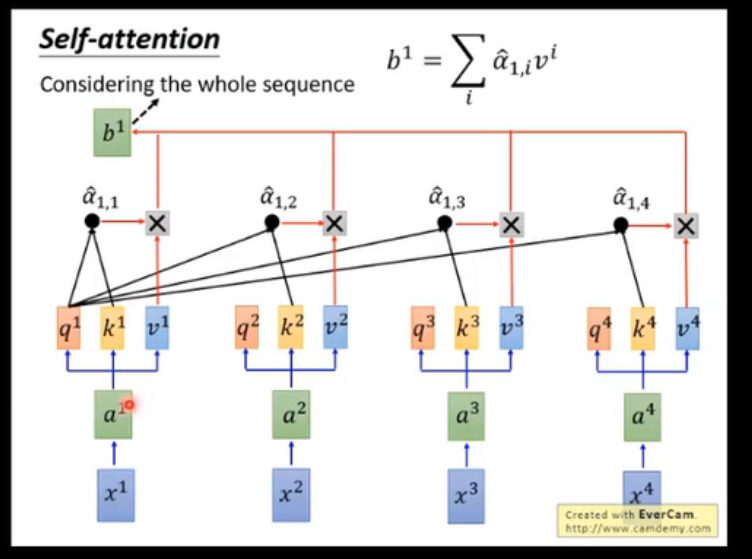
这就相当于考虑了整个句子了,这个整体就是一层的encoder block.
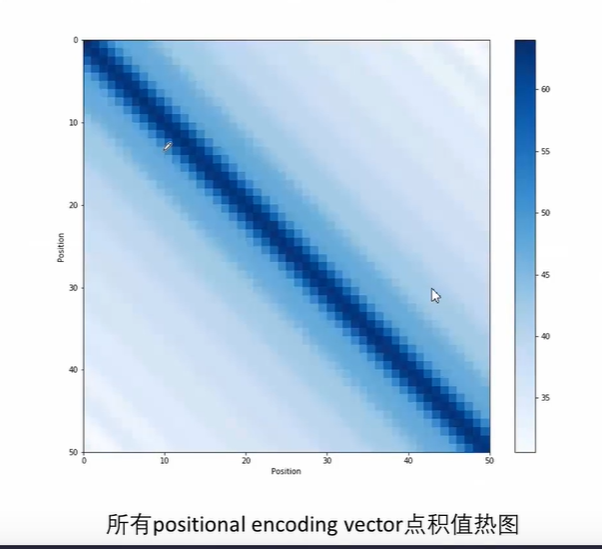
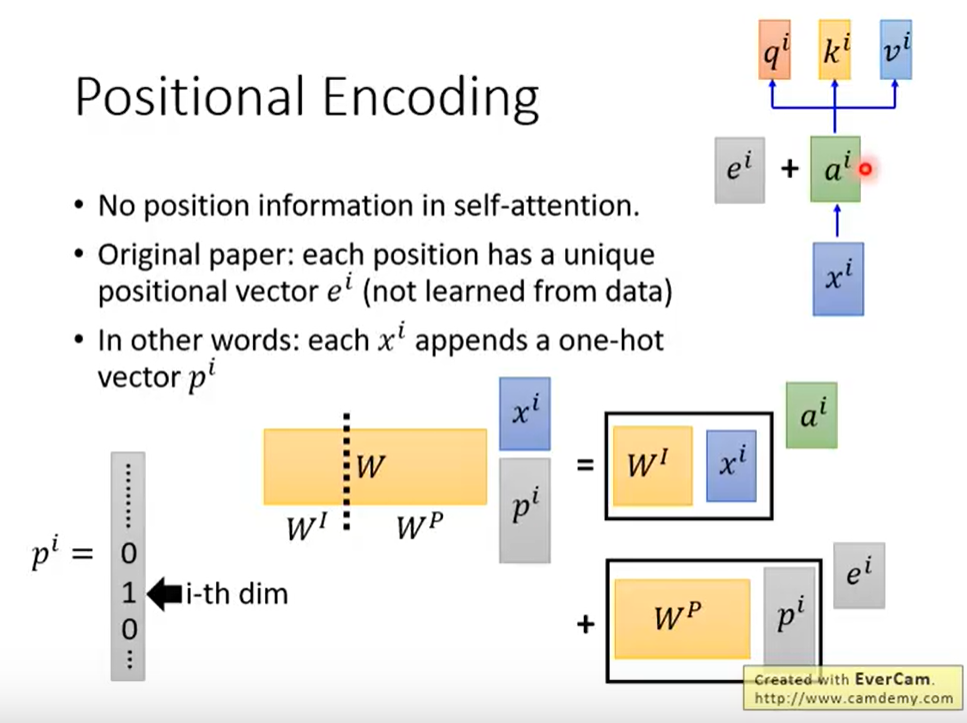
positional encoding
主要为了体现距离位置的信息,encoding向量之间点积越大代表距离越近
矩阵化操作
首先是矩阵化求看下面图很容易理解
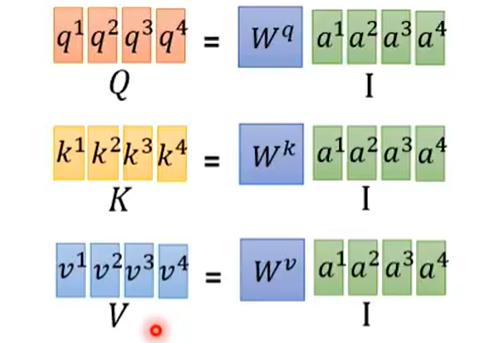
每个attention我们是通过,我们就可以个把堆积起来到一个矩阵和进行相乘得到attention向量
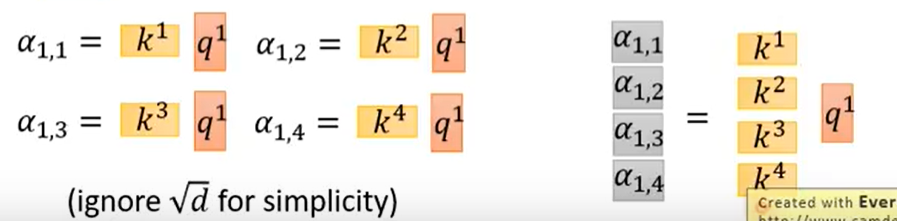
可以再进一步矩阵化,我们把也堆积起来到一个矩阵
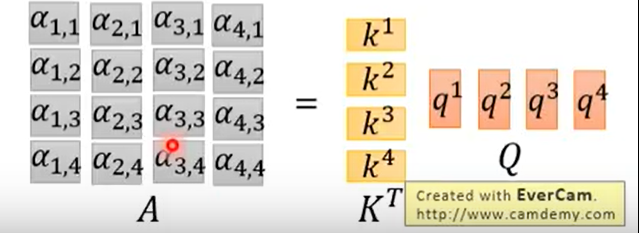
然后得到了attention score矩阵,每一个值都是两两个单词得到的attention值,除以,再对每一列求softmax。
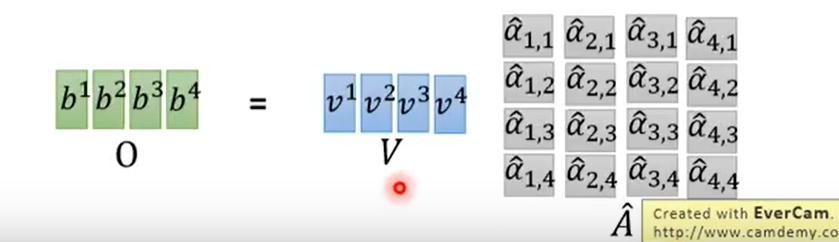
下面是对第一个单词的score向量分别与相乘得到(图里是),这里把堆积起来,最终得到整个self-attention layer输出O矩阵
总结起来就是:
multi-head attention
Multi-Head Attention相当于个不同的self-attention的集成(ensemble),然后将所有头得到的特征矩阵拼接起来,经过一层全连接后得到输出最终的.
优缺点
优点:
- 每一层计算复杂度比较低
- 比较利于并行计算
- 模型可解释性比较高
缺点:
- 有些RNN可以轻易解决的问题transformer没做到,比如复制string,或者推理时遇到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
- RNN图灵完备,而transformer不是
疑惑
attention考虑到了所有两两单词,无论是邻居还是远在天涯,但这样没有考虑单词的顺序了?
原始文章:加上位置向量,这不是学出来的参数,是人工加上的
transformer和lstm可以说是一个并列的模型,也就是一定意义上可以相互替代
原论文:https://arxiv.org/abs/1706.03762
参考文献:https://jalammar.github.io/illustrated-transformer/ 翻译:https://blog.csdn.net/longxinchen_ml/article/details/86533005
参考视频:
台大李宏毅老师-深度学习HLP

