引言
parallel
parallel表示其后语句将被多个线程并行执行,“#pragma omp parallel”后面的语句(或者,语句块)被称为parallel region。
多个线程的执行顺序是不能保证的。
for
我们一般是对一个计算量庞大的任务进行划分,让多个线程分别执行计算任务的某一部分,从而达到缩短计算时间的目的。这里的关键是,每个线程执行的计算互不相同(操作的数据不同或者计算任务本身不同),多个线程协作完成所有计算。
OpenMP for指示将C++ for循环的多次迭代划分给多个线程(划分指,每个线程执行的迭代互不重复,所有线程的迭代并起来正好是C++ for循环的所有迭代),这里C++ for循环需要一些限制从而能在执行C++ for之前确定循环次数,例如C++ for中不应含有break等。
测试下电脑是几核的(几线程)
c++
1 |
|

参考文献:https://blog.csdn.net/laobai1015/article/details/79020128
问题分析
矩阵求逆大致有三个方法,待定系数法、伴随矩阵求逆矩阵,初等变换求逆矩阵。而待定系数法和伴随矩阵对维数大很难计算了,而初等变化法有着清晰的过程,比较容易用编程语言表达,并且遍历矩阵去操作归一化清零等过程可以很容易实现并行化,不同线程的操作是针对不同行和列也不会产生冲突导致错误。
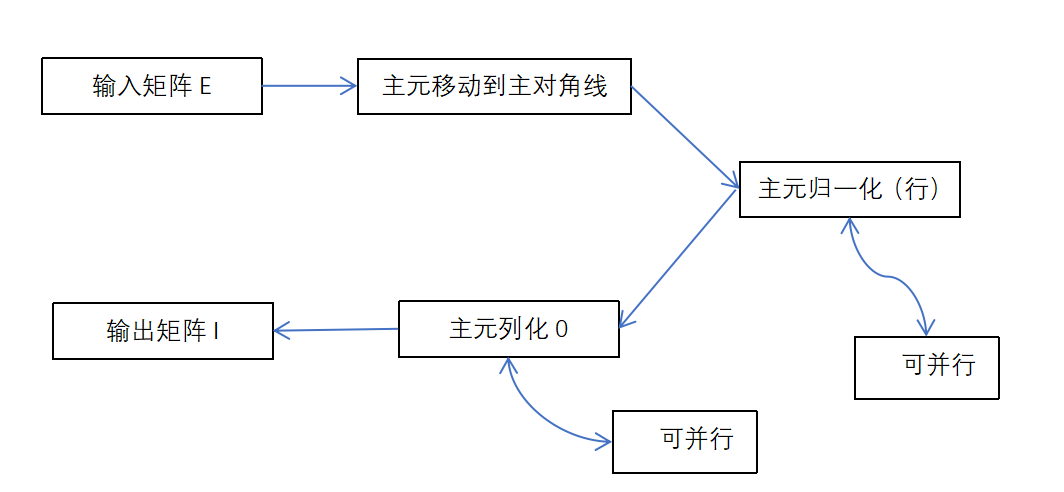
实现方案:
使用高斯消元法,用二维vector来存储矩阵,方便实现矩阵维度的变化以及遍历,将可并行化的循环加上#pragma omp parallel for实现并行化。
代码思路

运行加速比和正确性验证
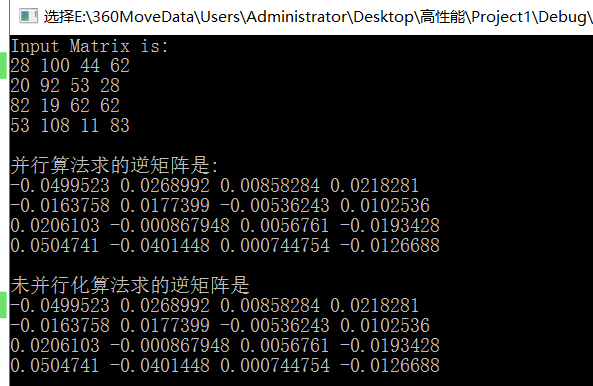

代码基于c++和openmp编写,需要代码邮件call我~

