深度学习有许多应用,这些应用往往包括以某种形式获取数据(例如图像或文本),并以另一种形式生成数据(例如标签,数字或更多文本)。从这个角度来看,深度学习包括构建一个将数据从一种表示转换为另一种表示的系统。
从一种数据形式到另一种数据形式的转换通常是由深度神经网络分层次学习的,这意味着我们可以将层次之间转换得到的数据视为一系列中间表示(intermediate representation)。以图像识别为例,浅层的表示可以是特征(例如边缘检测)或纹理(例如毛发),较深层次的表征可以捕获更复杂的结构(例如耳朵、鼻子或眼睛)。
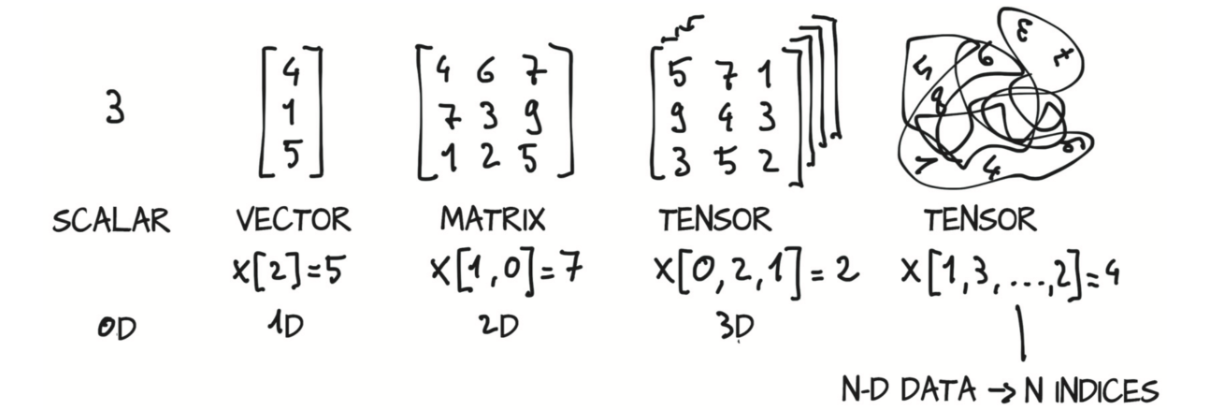
张量(tensor)
对于来自数学、物理学或工程学的人来说,张量一词是与空间、参考系以及它们之间的转换的概念是捆绑在一起的。对于其他人来说,张量是指将向量(vector)和矩阵(matrix)推广到任意维度,。与张量相同概念的另一个名称是多维数组(multidimensional array)。张量的维数与用来索引张量中某个标量值的索引数一致。
张量的优点
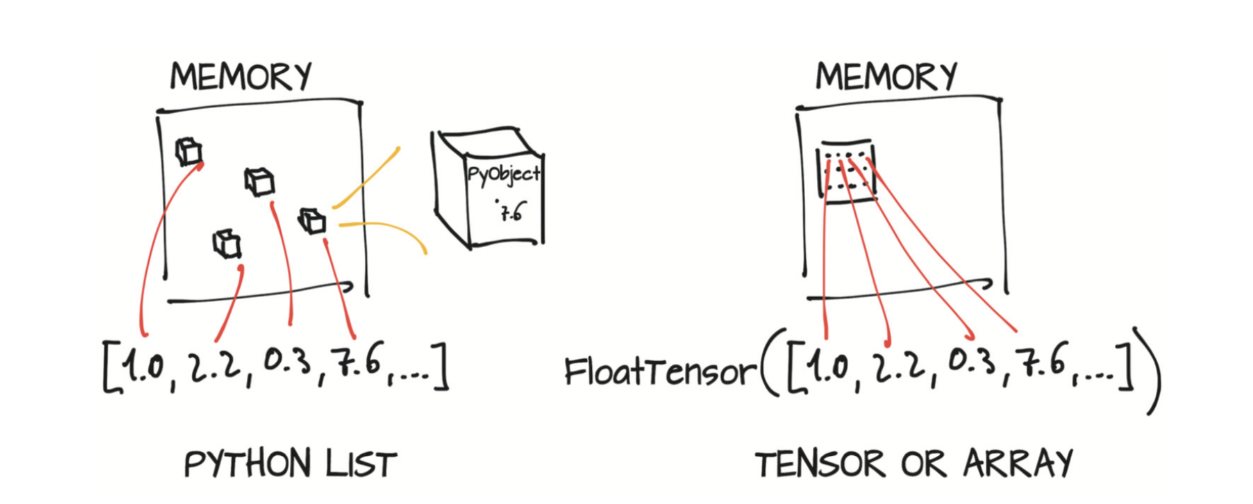
Python列表或数字元组(tuple)是在内存中单独分配的Python对象的集合,如图2.3左侧所示。然而,PyTorch张量或NumPy数组(通常)是连续内存块上的视图(view),这些内存块存有未封装(unboxed)的C数值类型,在本例中,如图2.3右侧所示,就是32位的浮点数(4字节),而不是Python对象。因此,包含100万个浮点数的一维张量需要400万个连续字节存储空间,再加上存放元数据(尺寸、数据类型等)的少量开销。
比如可以用zeros或ones来初始化张量,同时用元组指定大小
1 | points = torch.zeros(3, 2) |
输出:
1 | tensor([[0., 0.], |
函数名后面带下划线_ 的函数会修改Tensor本身,例如,x.add_(y)和x.t_()会改变 x,但x.add(y)和x.t()返回一个新的Tensor, 而x不变。
Tensor和numpy对象共享内存,所以他们之间的转换很快,而且几乎不会消耗什么资源。但这也意味着,如果其中一个变了,另外一个也会随之改变。

