k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割,k < n。假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。通过迭代的方式将样本分到K个簇。
选取K个点做为初始聚集的簇心(也可选择非样本点);
分别计算每个样本点到 K个簇核心的距离(这里的距离一般取欧氏距离或余弦距离),找到离该点最近的簇核心,将它归属到对应的簇;
所有点都归属到簇之后, M个点就分为了 K个簇。之后重新计算每个簇的重心(平均距离中心),将其定为新的“簇核心”;
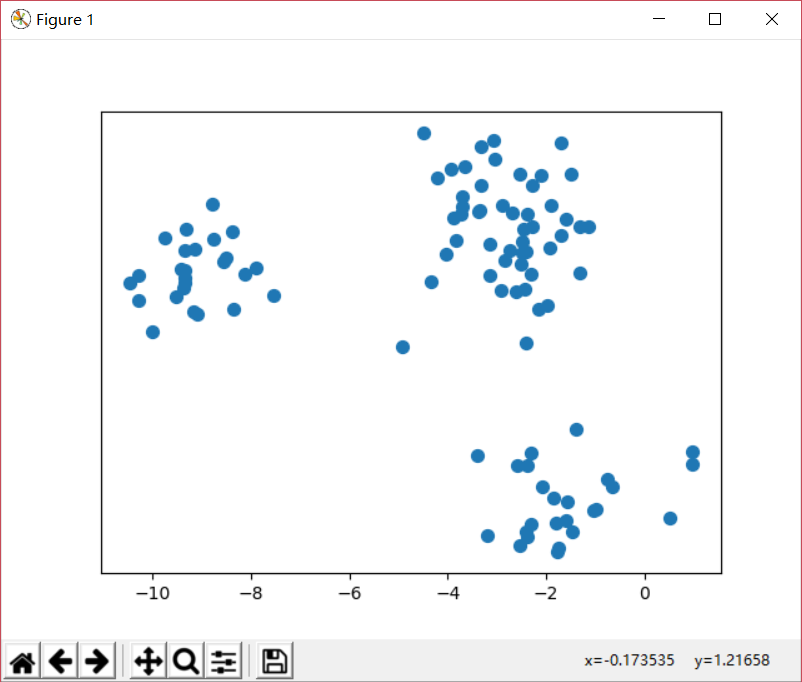
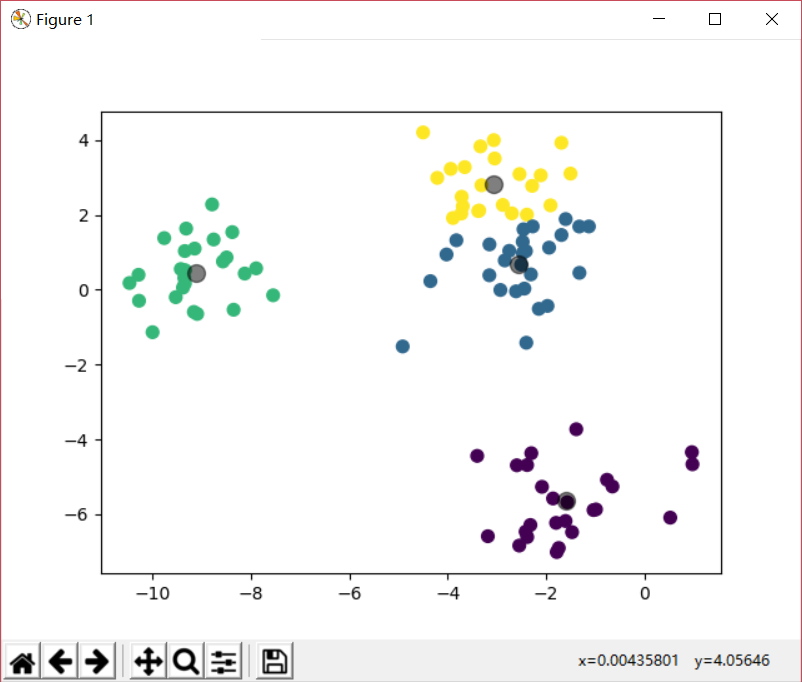
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import matplotlib.pyplot as pltfrom sklearn.datasets import make_blobsfrom sklearn.cluster import KMeansk=4 X,Y = make_blobs(n_samples=100 , n_features=2 , centers=k) km = KMeans(n_clusters=k, init='k-means++' , max_iter=300 ) km.fit(X) centroids = km.cluster_centers_ y_kmean = km.predict(X) print(y_kmean) plt.scatter(X[:, 0 ], X[:, 1 ], s=50 ) plt.yticks(()) plt.show() plt.scatter(X[:, 0 ], X[:, 1 ], c=y_kmean, s=50 , cmap='viridis' ) plt.scatter(centroids[:, 0 ], centroids[:, 1 ], c='black' , s=100 , alpha=0.5 ) plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import numpy as npfrom sklearn.datasets import make_blobsfrom math import sqrtimport randomimport matplotlib.pyplot as pltfrom scipy import spatialk=4 X,Y = make_blobs(n_samples=100 , n_features=2 , centers=k) def calcuDistance (vec1, vec2) : return np.sqrt(np.sum(np.square(vec1 - vec2))) def k_means (data,k,Y) : m, n = data.shape cores = data[np.random.choice(np.arange(m), k, replace=False )] print(cores) while True : distance = spatial.distance.cdist(data, cores,metric='euclidean' ) index_min = np.argmin(distance, axis=1 ) if (index_min == Y).all(): return Y, cores Y[:] = index_min for i in range(k): items = Y==i cores[i] = np.mean(data[items], axis=0 ) result,cores=k_means(X,k,Y) plt.scatter(X[:, 0 ], X[:, 1 ], s=50 ) plt.yticks(()) plt.show() print(Y) plt.scatter(X[:, 0 ], X[:, 1 ], c=Y, s=50 , cmap='viridis' ) plt.scatter(cores[:, 0 ], cores[:, 1 ], c='black' , s=100 , alpha=0.5 ) plt.show()
k-means改进的一个路线就是尽可能加快收敛速度,这个方向有几个思路: