graghsage
论文链接:https://arxiv.org/abs/1706.02216
github链接:https://github.com/williamleif/GraphSAGE
官方介绍链接:http://snap.stanford.edu/graphsage/
gcn
现存的方法需要图中所有的顶点在训练embedding的时候都出现;这些前人的方法本质上是transductive,不能自然地泛化到未见过的顶点。
GraphSAGE是为了学习一种节点表示方法,即如何通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练单独的embedding。
GCN虽然能提取图中顶点的embedding,但是存在一些问题:
- GCN的基本思想: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量表示。
- GCN的优点: 可以捕捉graph的全局信息,从而很好地表示node的特征。
- GCN的缺点: Transductive learning的方式,需要把所有节点都参与训练才能得到node embedding,无法快速得到新node的embedding。
GCN等transductive的方法,学到的是每个节点的一个唯一确定的embedding; 而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。
算法概述

:K是网络的层数,也代表着每个顶点能够聚合的邻接点的跳数,如K=2的时候每个顶点可以最多根据其2跳邻接点的信息学习其自身的embedding表示。每增加一层可以聚合更远节点的信息
:GraphSAGE中每一层的节点邻居都是是从上一层网络采样的,并不是所有邻居参与,并且采样的后的邻居的size是固定的
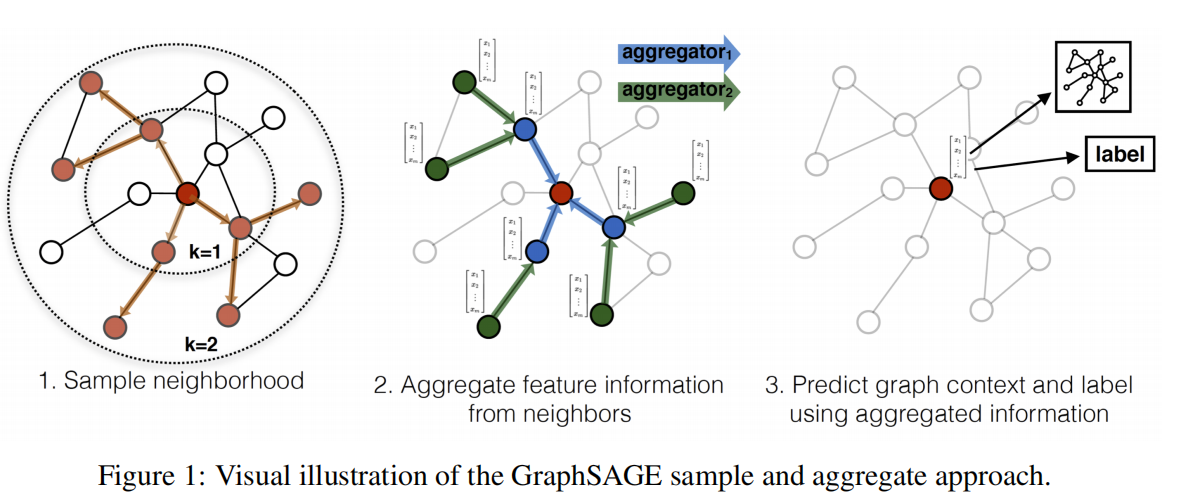
其运行流程如上图所示,可以分为三个步骤:
- 对图中每个顶点邻居顶点进行采样,因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居
- 根据聚合函数聚合邻居顶点蕴含的信息
- 得到图中各顶点的向量表示供下游任务使用
Neighborhood definition - 采样邻居顶点
出于对计算效率的考虑,对每个顶点采样一定数量的邻居顶点作为待聚合信息的顶点。设需要的邻居数量,即采样数量为SSS,若顶点邻居数少于SSS,则采用有放回的抽样方法,直到采样出SSS个顶点。若顶点邻居数大于SSS,则采用无放回的抽样。(即采用有放回的重采样/负采样方法达到SSS)
当然,若不考虑计算效率,完全可以对每个顶点利用其所有的邻居顶点进行信息聚合,这样是信息无损的。
文中在较大的数据集上实验。因此,统一采样一个固定大小的邻域集,以保持每个batch的计算占用空间是固定的(即 graphSAGE并不是使用全部的相邻节点,而是做了固定size的采样)。
这样固定size的采样,每个节点和采样后的邻居的个数都相同,可以把每个节点和它们的邻居拼成一个batch送到GPU中进行批训练。
论文里说固定长度的随机游走其实就是随机选择了固定数量的邻居
聚合函数的选取##
在图中顶点的邻居是无序的,所以希望构造出的聚合函数是对称的(即也就是对它输入的各种排列,函数的输出结果不变),同时具有较高的表达能力。 聚合函数的对称性(symmetry property)确保了神经网络模型可以被训练且可以应用于任意顺序的顶点邻居特征集合上。
主要有mean embedding,LSTM,pooling

