激活函数(Activation functions)
如果不使用激活函数,无论神经网络多少层都会是个线性激活函数

最基本的线性回归函数,一般用在最后一层。
除了二分类问题,不要使用sigmoid,tanh变现总是更好,但这些函数当z很大时,梯度会很小,训练会很慢,所以推荐relu函数。
ReLu函数只要是正值的情况下,导数恒等于1,当是负值的时候,导数恒等于0。从实际上来说,当使用的导数时,=0的导数是没有定义的。但是当编程实现的时候,的取值刚好等于0.00000001,这个值相当小,所以,在实践中,不需要担心这个值,是等于0的时候,假设一个导数是1或者0效果都可以。这里也有另一个版本的Relu被称为Leaky Relu,这个函数通常比Relu激活函数效果要好,尽管在实际中Leaky ReLu使用的并不多.
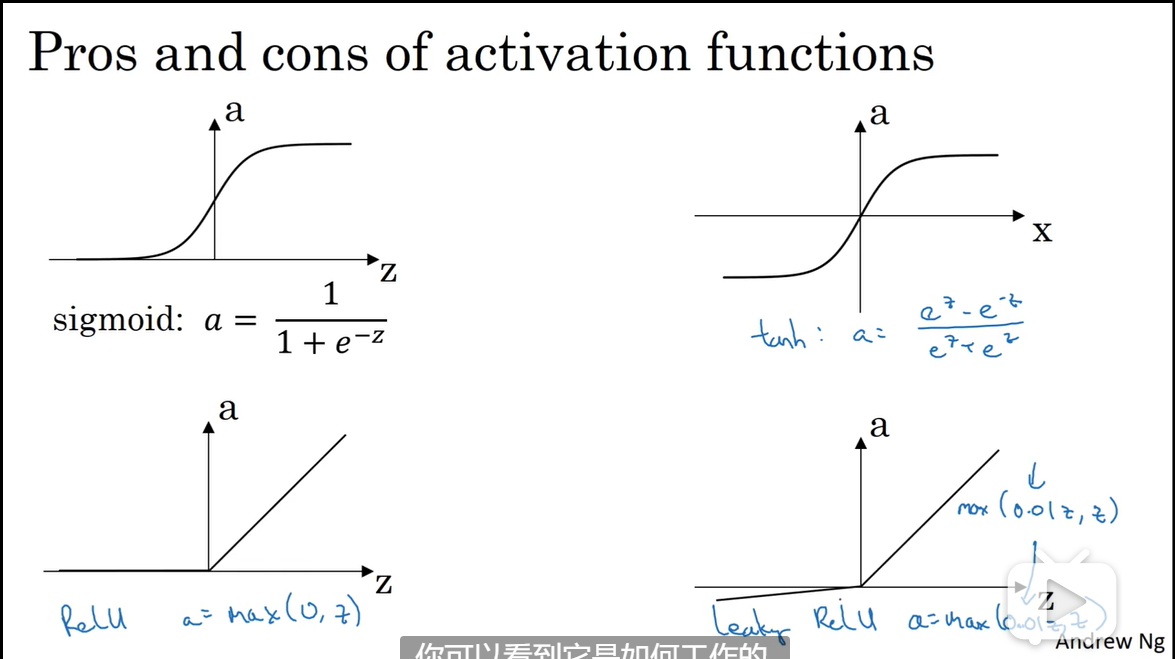
对于sigmoid函数,他的导数等于
对于tanh函数,他的导数等于
Relu函数,leaky Relu函数
- 下限为0,无上限
- 严格递增
- sparse activation
softmax也可以当作激活函数来看,用在分类问题
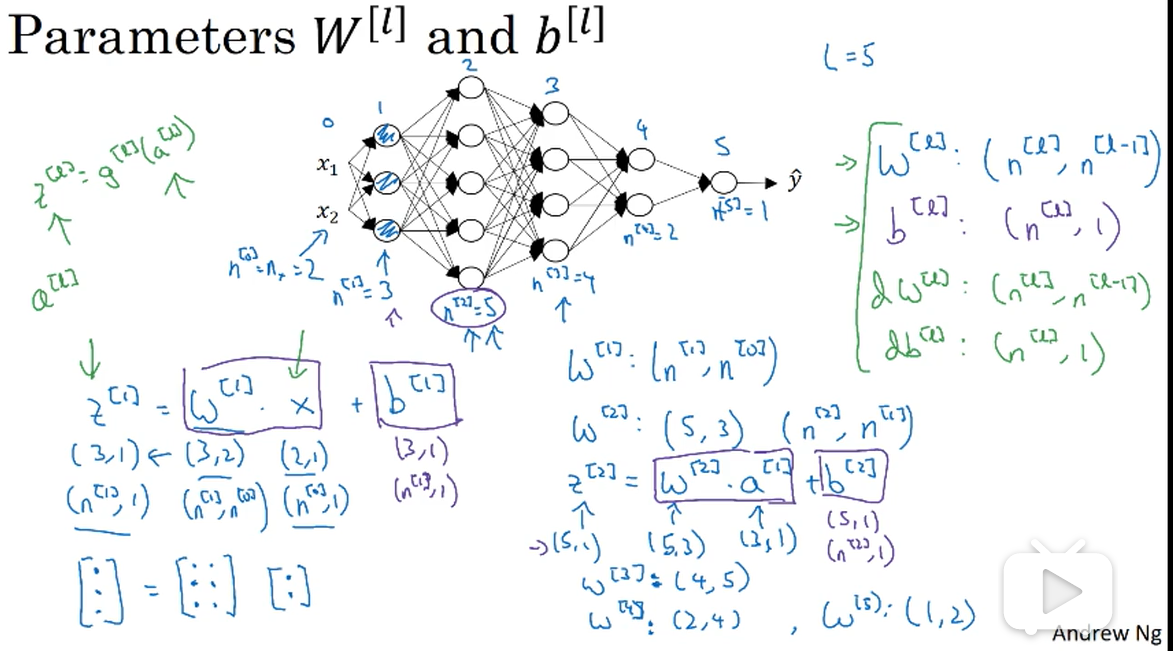
矩阵的维数
比如图中的神经网络,第一个隐藏层,是3×1的矩阵,是2×1的矩阵,所以是3×2的,总结起来就是是的,对也是一样的,就是的,见图片右半部分
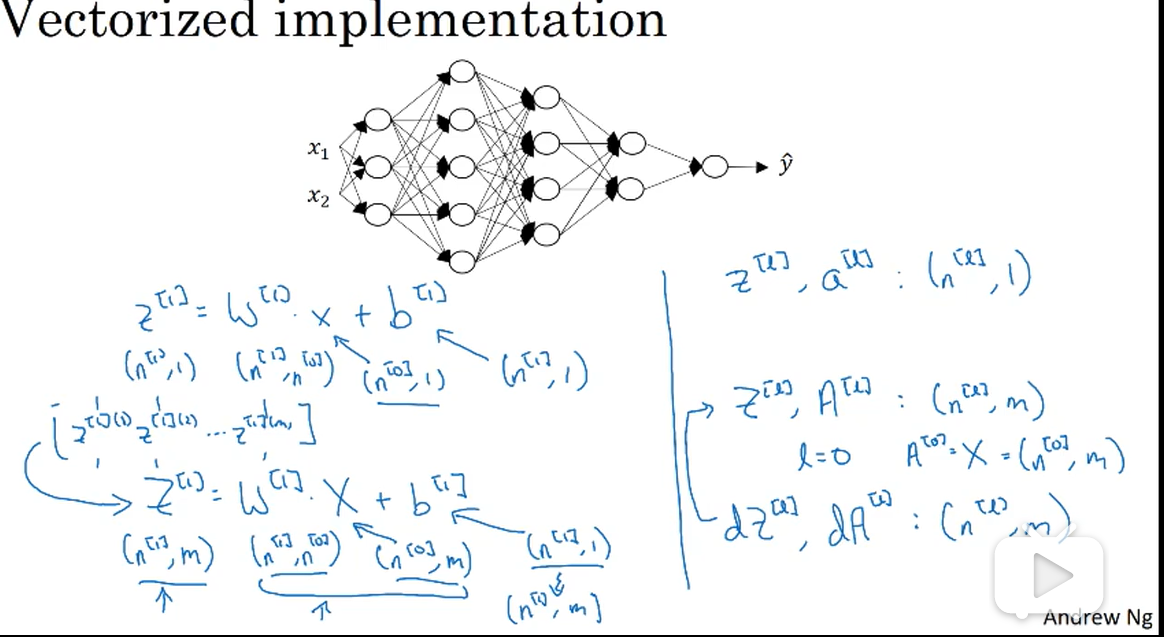
之后可以将叠加起来,m为样本数量
参数随机初始化(Random+Initialization)
为什么是0.01,而不是100或者1000。我们通常倾向于初始化为很小的随机数。因为如果你用tanh或者sigmoid激活函数,或者说只在输出层有一个Sigmoid,如果很大,就会很大或者很小,因此这种情况下你很可能停在tanh/sigmoid函数的平坦的地方(见图3.8.2),这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
正则化(Regularization)
1.为什么只正则化参数?为什么不再加上参数呢?你可以这么做,只是我习惯省略不写,因为通常是一个高维参数矢量,已经可以表达高偏差问题,可能包含有很多参数,我们不可能拟合所有参数,而只是单个数字,所以几乎涵盖所有参数,而不是,如果加了参数,其实也没太大影响,因为只是众多参数中的一个,所以我通常省略不计,如果你想加上这个参数,完全没问题。
2.为什么正则化会有用?当增大,接近于0,会减少很多隐藏单元的影响,网络会变得简单,接近于逻辑回归,也会很小(),会呈线性。
3.其他正则化方法:数据扩增(比如图片翻转、裁剪、扭曲),early stop
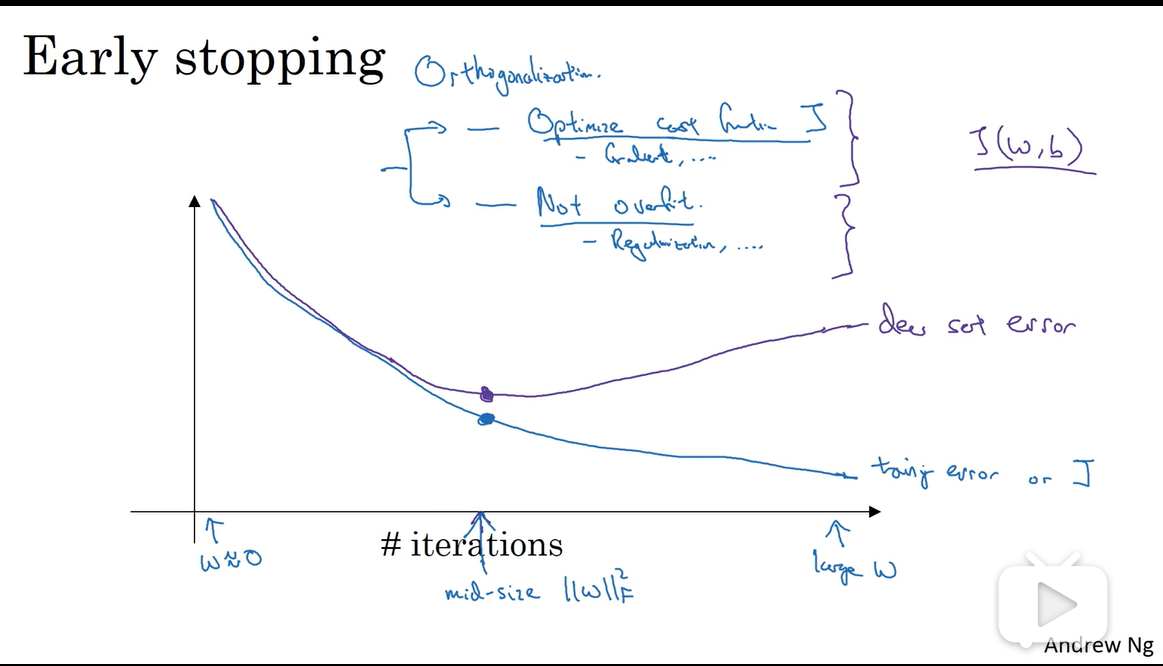
early stop无法将降低损失函数和过拟合独立处理,会很复杂,所以更倾向L2正则化,虽然要尝试很多不同的,计算代价会很大
归一化
为什么要归一化?代价函数看起来会更对称,无论从哪个位置开始都能更直接的找到最小值,可以使用较大的步长。
padding
普通的卷积两个缺点,第一个缺点是每次做卷积操作,你的图像就会缩小,从6×6缩小到4×4,你可能做了几次之后,你的图像就会变得很小了,可能会缩小到只有1×1的大小。你可不想让你的图像在每次识别边缘或其他特征时都缩小,这就是第一个缺点。第二个缺点时,如果你注意角落边缘的像素,这个像素点只被一个输出所触碰或者使用,因为它位于这个3×3的区域的一角。但如果是在中间的像素点,就会有许多3×3的区域与之重叠。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。
对于的图像,的filter(通常为奇数),paddy为p,步长stride为2,最后得到的矩阵为,如果这个不是整数,我们向下取整,
损失函数

