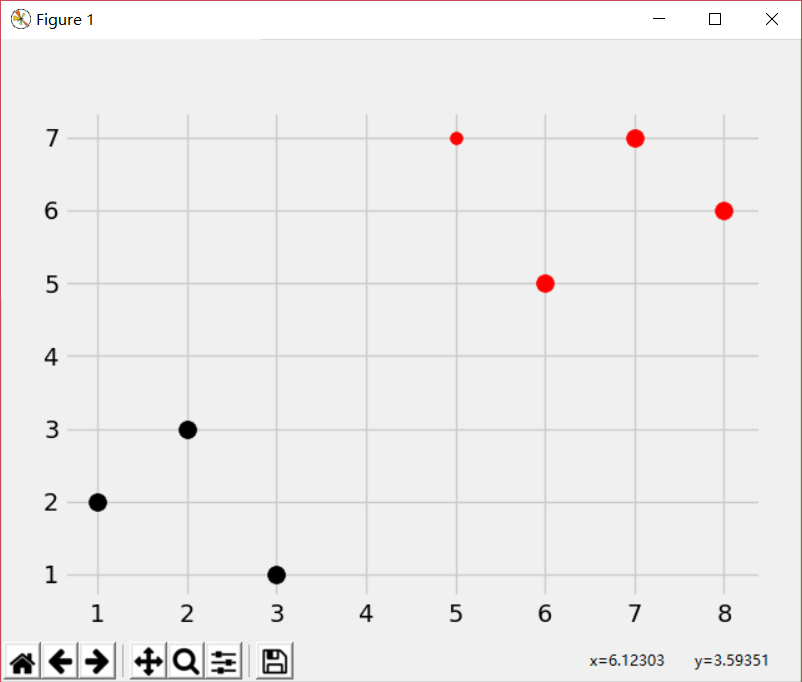
import numpy as np from math import sqrt import matplotlib.pyplot as plt import warnings from matplotlib import style from collections import Counter style.use('fivethirtyeight') dataset = {'k':[[1,2],[2,3],[3,1]], 'r':[[6,5],[7,7],[8,6]]} new_features = [5,7] for i in dataset: for ii in dataset[i]: plt.scatter(ii[0],ii[1],s=100,color=i)
defk_nearest_neighbors(data, predict, k=3): if len(data) >= k: warnings.warn('K is set to a value less than total voting groups!') distances = [] for group in data: for features in data[group]: euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict)) #欧几里得距离 distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]] vote_result = Counter(votes).most_common(1)[0][0] #不使用[0][0],得到的是[('r', 3)]. [0][0]得到元组中第一个元素 return vote_result
result = k_nearest_neighbors(dataset,new_features,k=3) print(result) plt.scatter(new_features[0],new_features[1],s=50,color=result)#预测的数据用小红点表示 plt.show()
import numpy as np import matplotlib.pyplot as plt from matplotlib import style import warnings from collections import Counter import pandas as pd import random
defk_nearest_neighbors(data, predict, k=3): if len(data) >= k: warnings.warn('K is set to a value less than total voting groups!') distances = [] for group in data: for features in data[group]: euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict)) distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]] vote_result = Counter(votes).most_common(1)[0][0] #不使用[0][0],得到的是[('r', 3)]. [0][0]得到元组中第一个元素 return vote_result
test_size = 0.2 train_set = {2:[], 4:[]}#良性恶性两个lable test_set = {2:[], 4:[]} train_data = full_data[:-int(test_size*len(full_data))] test_data = full_data[-int(test_size*len(full_data)):] #最后20% correct = 0 total = 0 for i in train_data: train_set[i[-1]].append(i[:-1]) #去掉label,将属性填入
for i in test_data: test_set[i[-1]].append(i[:-1])
for group in test_set: for data in test_set[group]: vote = k_nearest_neighbors(train_set, data, k=5) if group == vote: correct += 1 total += 1 print('Accuracy:', correct/total)