核心思想:map each node in a network into a low-dimensional space把每个节点映射到低维空间
在学习一个网络表示的时候需要注意的几个性质:
- 适应性,网络表示必须能适应网络的变化。网络是一个动态的图,不断地会有新的节点和边添加进来,网络表示需要适应网络的正常演化。
- 属于同一个社区的节点有着类似的表示。网络中往往会出现一些特征相似的点构成的团状结构,这些节点表示成向量后必须相似。
- 低维。代表每个顶点的向量维数不能过高,过高会有过拟合的风险,对网络中有缺失数据的情况处理能力较差。
- 连续性。低维的向量应该是连续的。
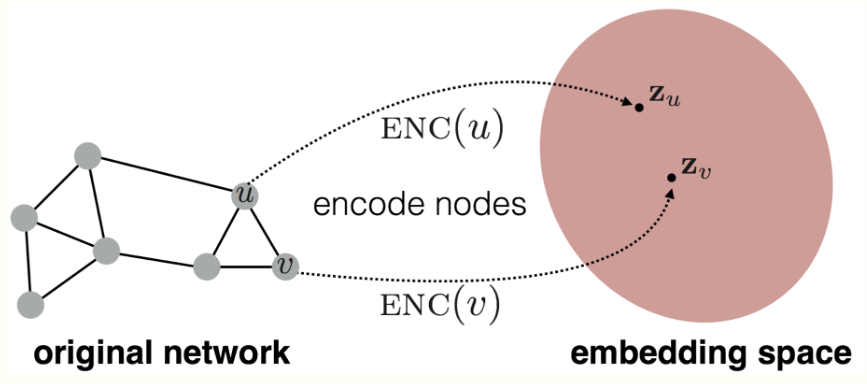
Embedding Nodes
node embedding的目标是在原网络的similarity近似于embedding space的相似度(内积)
1.定义一个encoder(i.e., a mapping from nodes to embeddings)
2.定义相似度函数(原始网络中的相似度)
3.优化encoder的参数,使得原始网络中u,v的相似度近似于embedding的点积
deep walk
given a graph and a starting point, we select a neighbor of it at random, and move to this neighbor; then we select a neighbor of this point at random, and move to it, etc. The (random) sequence of points selected this way is a random walk on the graph. So is defined as the probability that
u and v co-occur on a random walk over a network.
思想来源于语言模型,我们想要在所有训练短语中最大化概率,The direct analog is to estimate the likelihood of observing vertex vi given all the previous vertices visited so far in the random walk.
deep walk中算法主要包括两个部分,一个是random walk gengerator,第二个是更新程序.
deep walk 论文笔记
random-walk embeddings有如下几步:
1.Estimate probability of visiting node v on a random walk starting from node u using some random walk strategy R. The simplest idea is just to run fixed-length, unbiased random walks starting from each node i.e., DeepWalk from Perozzi et al., 2013
2.Optimize embeddings to encode these random walk statistics, so the similarity between embeddings (e.g., dot product) encodes Random Walk similarity.
deep walk配置
-
首先克隆代码到本地,进入目录
CodeC:\Users\Administrator\Downloads\deepwalk-master``` 1
2. 执行```pip install -r requirements.txt
-
执行
pythonsetup.py install``` 1
4. 执行```deepwalk --input example_graphs/karate.adjlist --output karate.embeddings
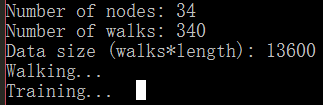
embedding结果:

代码的解读:https://blog.csdn.net/github_36326955/article/details/82702379
Random walk optimization and Negative Sampling
待更新
Node2vec
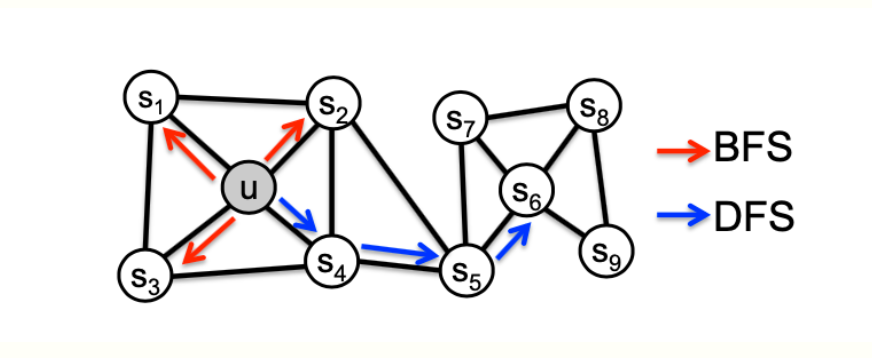
考虑灵活变长的random walk,可以权衡网络的局部和全局的结构,有两种策略BFS,DFS
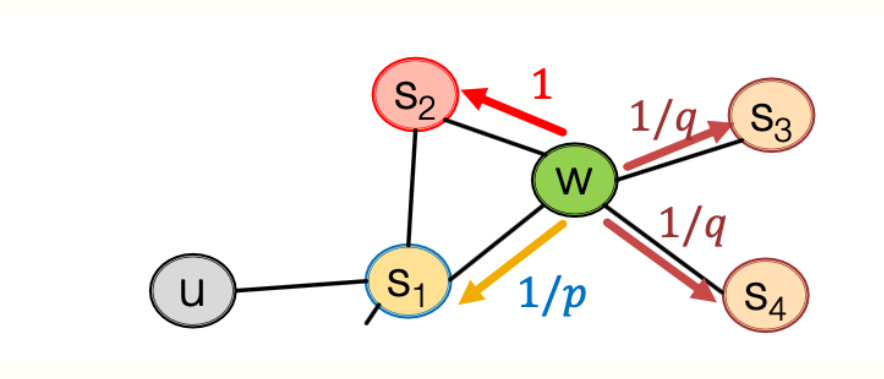
定义两个参数,p为返回之前节点的概率,q来调节DFS,BFS
算法:
1.估算random walk概率
2.对于每个节点u模拟r次长度为l的random walk
3.使用随机梯度下降进行更新

